
Jan-v2-VL
Collection
Jan-v2-VL: a family of VLM focused on reliable, many-step task execution. • 9 items • Updated • 40

Jan-v2-VL is an 8B-parameter vision–language model for long-horizon, multi-step tasks in real software environments (e.g., browsers and desktop apps). It combines language reasoning with visual perception to follow complex instructions, maintain intermediate state, and recover from minor execution errors.
We recognize the importance of long-horizon execution for real-world tasks, where small per-step gains compound into much longer successful chains—so Jan-v2-VL is built for stable, many-step execution. For evaluation, we use The Illusion of Diminishing Returns: Measuring Long-Horizon Execution in LLMs, which measures execution length. This benchmark aligns with public consensus on what makes a strong coding model—steady, low-drift step execution—suggesting that robust long-horizon ability closely tracks better user experience.
Variants
Tasks where the plan and/or knowledge can be provided up front, and success hinges on stable, many-step execution with minimal drift:

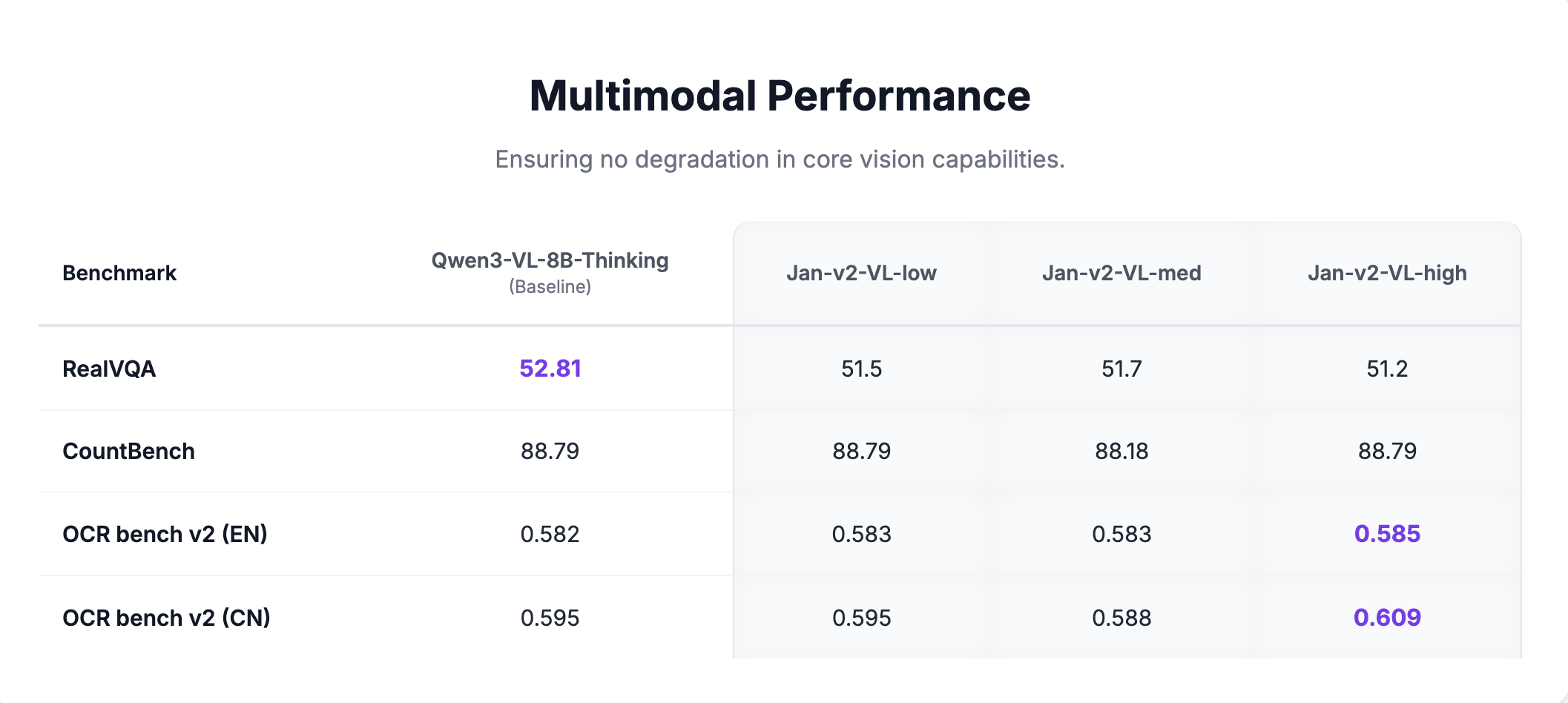
Compared with its base (Qwen-3-VL-8B-Thinking), Jan-v2-VL shows no degradation on standard text-only and vision tasks—and is slightly better on several—while delivering stronger long-horizon execution on the Illusion of Diminishing Returns benchmark.


Jan-v2-VL is optimized for direct integration with the Jan App. Simply select the model from the Jan App interface for immediate access to its full capabilities.
Using vLLM:
vllm serve Menlo/Jan-v2-VL-high \
--host 0.0.0.0 \
--port 1234 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--reasoning-parser qwen3
Using llama.cpp:
llama-server --model Jan-v2-VL-high-Q8_0.gguf \
--vision-model-path mmproj-Jan-v2-VL-high.gguf \
--host 0.0.0.0 \
--port 1234 \
--jinja \
--no-context-shift
For optimal performance in agentic and general tasks, we recommend the following inference parameters:
temperature: 1.0
top_p: 0.95
top_k: 20
repetition_penalty: 1.0
presence_penalty: 1.5
Updated Soon