
Lemur: Harmonizing Natural Language and Code for Language Agents
Paper • 2310.06830 • Published • 33
![]()
📄Paper: https://arxiv.org/abs/2310.06830
👩💻Code: https://github.com/OpenLemur/Lemur
First, we have to install all the libraries listed in requirements.txt in GitHub:
pip install -r requirements.txt
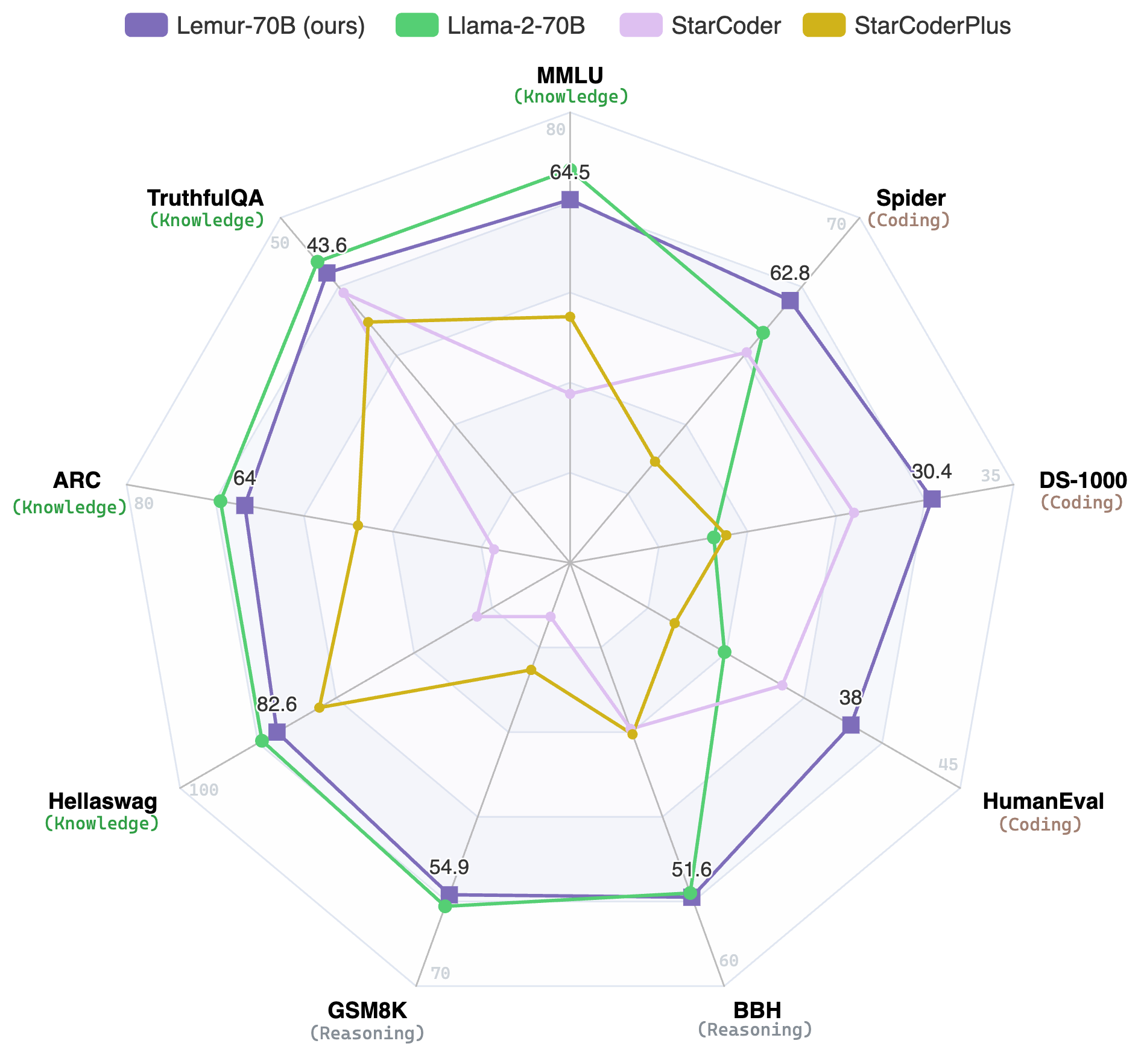
Since it is not trained on instruction following corpus, it won't respond well to questions like "What is the Python code to do quick sort?".
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("OpenLemur/lemur-70b-v1")
model = AutoModelForCausalLM.from_pretrained("OpenLemur/lemur-70b-v1", device_map="auto", load_in_8bit=True)
# Text Generation Example
prompt = "The world is "
input = tokenizer(prompt, return_tensors="pt")
output = model.generate(**input, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
# Code Generation Example
prompt = """
def factorial(n):
if n == 0:
return 1
"""
input = tokenizer(prompt, return_tensors="pt")
output = model.generate(**input, max_length=200, num_return_sequences=1)
generated_code = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_code)
The model is licensed under the Llama-2 community license agreement.
The Lemur project is an open collaborative research effort between XLang Lab and Salesforce Research. We thank Salesforce, Google Research and Amazon AWS for their gift support.